Agent Maturity Model
Part 7 / Team PracticesFive levels of agent maturity
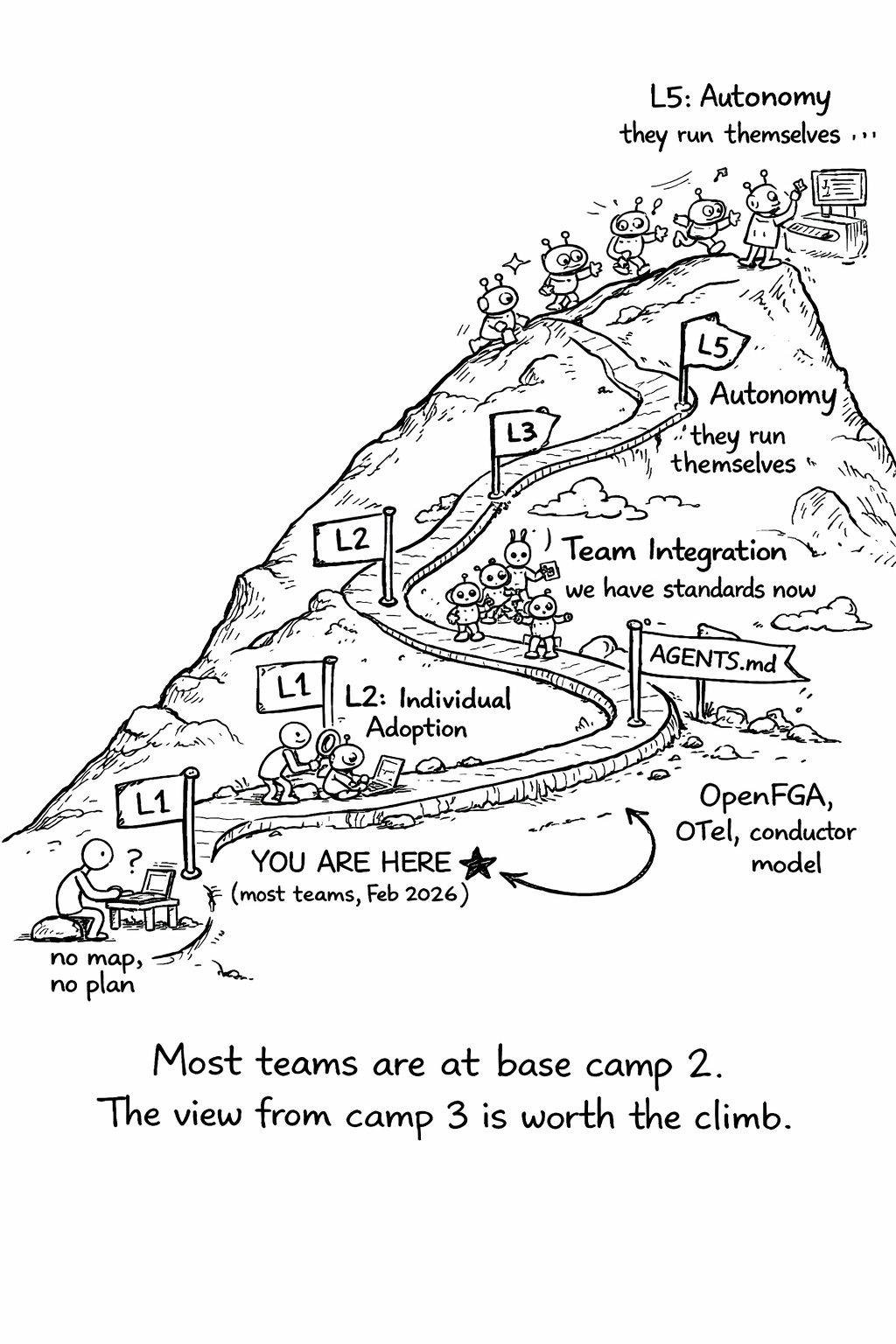
Agent maturity isn’t binary - you don’t go from “no agents” to “fully autonomous” overnight. Teams progress through five distinct levels, each with its own capabilities, risks, and organizational requirements. Understanding where your team is on this curve helps you prioritize investments and avoid the common mistake of jumping to Level 4 practices when you’re still at Level 2.
Level 1 is experimentation - individual engineers trying AI coding assistants on their own, with no team coordination, no security controls, and no cost tracking. Level 2 is individual adoption - engineers using agents regularly for personal productivity, with some informal knowledge sharing but no team-wide standards. Level 3 is team integration - AGENTS.md files in every repository, MCP servers for internal tools, basic review guidelines, and cost tracking. Level 4 is orchestration - multi-agent workflows, formal authorization with OpenFGA, full observability with OpenTelemetry, and the conductor model as the default working style. Level 5 is autonomy - background agents running unattended, anomaly detection and auto-remediation, outcome-based review, and continuous self-improvement of context and tooling.
Most teams in February 2026 are at Level 2 or early Level 3. The gap between Level 2 and Level 3 is where most value is captured - it’s the difference between “some engineers use AI” and “the team has agent infrastructure.” The gap between Level 3 and Level 4 is where most risk is managed - it’s the difference between “we use agents” and “we use agents safely.”
Maturity assessment
| Dimension | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|---|
| Usage | Experimenting | Individual | Team-wide | Multi-agent | Autonomous |
| Context | None | Ad hoc prompts | AGENTS.md | Knowledge graph | Self-updating |
| Security | None | None | Basic auth | OpenFGA | Full defense-in-depth |
| Observability | None | None | Basic logging | Full tracing | Anomaly detection |
| Cost | Unknown | Unknown | Tracked | Budgeted | Optimized |
| Review | None | Ad hoc | Guidelines | Formal policy | Automated + human |
| Policies | None | None | Informal | Documented | Enforced |
Moving up the maturity curve
Level 1 → Level 2: Individual adoption
Actions: - Install IDE-integrated agents (Cursor, Copilot, Claude Code) - Start with low-risk tasks (documentation, tests, simple bug fixes) - Track personal productivity changes
Timeline: 2-4 weeks
Level 2 → Level 3: Team integration
Actions: - Add AGENTS.md to all repositories - Set up MCP servers for internal APIs - Establish basic review guidelines - Implement basic cost tracking - Add agents to CI/CD (automated pre-review)
Timeline: 1-2 months
Level 3 → Level 4: Orchestration
Actions: - Deploy multi-agent workflows - Implement OpenFGA authorization - Set up full OpenTelemetry tracing - Formalize review policies (two-layer model) - Implement cost budgets and alerts - Train team on conductor skills
Timeline: 2-4 months
Level 4 → Level 5: Autonomy
Actions: - Deploy background agents (async, unattended) - Implement full defense-in-depth security - Build anomaly detection and auto-remediation - Shift to outcome-based review (review results, not actions) - Continuous context improvement
Timeline: 6+ months
What Level 5 looks like in practice: At Level 5, agents are part of the team’s daily workflow in the same way that CI/CD is part of the deployment workflow - always running, mostly invisible, and intervened with only when something goes wrong. Background agents monitor the repository for issues, automatically fix simple bugs, generate tests for new code, update documentation when code changes, and create PRs for routine maintenance tasks. Engineers review the PRs in batch, approving the ones that look good and providing feedback on the ones that don’t.
The key difference between Level 4 and Level 5 is trust. At Level 4, engineers actively supervise agents - they specify tasks, monitor progress, and review output in real-time. At Level 5, engineers trust agents to work independently and review output asynchronously. This trust is earned through months of data - high acceptance rates, low defect rates, and zero security incidents. It can’t be shortcut.
The maturity trap
A common mistake is trying to skip levels. A team at Level 2 (individual adoption) that tries to jump to Level 4 (orchestration) will fail - they don’t have the infrastructure (AGENTS.md, MCP servers, authorization, observability) that Level 4 requires. Each level builds on the previous one, and the infrastructure from earlier levels is a prerequisite for later levels.
Another common mistake is measuring maturity by the most advanced capability rather than the weakest dimension. A team that has Level 4 usage but Level 1 security is not at Level 4 - they’re at Level 1 with a dangerous gap. Maturity should be measured by the lowest dimension, not the highest. The maturity assessment table helps identify these gaps.
Decision records for the agent era
Architecture Decision Records (ADRs) need adaptation for a world where agents make implementation decisions. Traditional ADRs document human decisions - “we chose PostgreSQL over MongoDB because…” Agent-era ADRs need to document two additional things: what decisions are delegated to agents (and what constraints apply), and what decisions agents made that humans should review.
A good agent-era ADR includes the decision context, the options considered, the chosen option and rationale, the agent delegation policy (which aspects of implementation are delegated to agents, and what constraints they must follow), and the review criteria (what a human reviewer should check in the agent’s implementation of this decision).
This matters because agents make implementation decisions constantly - which data structure to use, how to handle errors, what naming conventions to follow. Without explicit guidance, these decisions are made based on the model’s training data, which may not match your team’s preferences. ADRs that include agent delegation policies ensure that agents make implementation decisions that are consistent with your architectural intent.
Maturity assessment
The maturity assessment is a self-evaluation tool. Score your team on each dimension, identify the lowest scores, and focus your investment there. A team that’s Level 4 on usage but Level 1 on security has a dangerous gap. A team that’s Level 3 across the board is well-positioned to move to Level 4 systematically.
Related Concepts: AI Fatigue (20.1), Conductor Model (21.1) Related Workflows: Measuring Agent Impact (Chapter 25), Agent Adoption Playbook (Chapter 33)
“From demo to deployed. Step by step.”
This section contains actionable workflows, checklists, and templates. Each workflow takes an engineering team from “we want to do X” to “X is running in production.”