Multi-Agent Systems
Part 6 / Agent OrchestrationWhen to use multiple agents
Single agents work well for focused tasks. Multi-agent systems are needed when:
| Scenario | Why Multiple Agents |
|---|---|
| Different expertise needed | Security agent + code agent + test agent |
| Parallel execution | Multiple independent subtasks |
| Separation of concerns | Each agent has limited permissions |
| Adversarial checking | One agent reviews another’s work |
| Long-running workflows | Agents hand off across time boundaries |
Fleet-Scale parallelism
Before diving into architectures, it’s worth noting the scale dimension. Some tasks aren’t complex - they’re repetitive. Migrating 200 microservices from Java 8 to Java 17. Patching a CVE across every repository. Updating documentation org-wide. Adding input validation to every API endpoint. Upgrading a dependency across the entire organization.
These tasks don’t need sophisticated multi-agent coordination. They need fleet-scale parallelism: hundreds of identical agents running the same playbook against different targets simultaneously. Platforms like Ona support this natively - spin up an isolated environment per repository, run the migration agent, collect the PRs. Work that would take a team weeks finishes in hours.
The key requirement is isolation. Each agent must run in its own environment so a failure in one repository doesn’t affect others. If the migration agent crashes on repository 47, repositories 1-46 and 48-200 should be unaffected. Ephemeral environments (Chapter 10) provide this isolation naturally - each agent gets a fresh environment that’s destroyed when the task completes.
Fleet-scale parallelism changes the economics of large-scale changes. A CVE patch that affects 200 repositories used to require a dedicated engineer for a week - creating the patch, testing it in each repository, opening PRs, responding to review feedback. With fleet-scale agents, the same work completes in hours: define the patch playbook once, run it against all 200 repositories in parallel, review the PRs in batch. The engineer’s role shifts from doing the work to defining the playbook and reviewing the results.
The playbook design is critical. A good playbook is idempotent (running it twice produces the same result), testable (you can verify the playbook on a single repository before running it at scale), and observable (you can see the status of every repository in a dashboard). A bad playbook - one that makes assumptions about repository structure, doesn’t handle edge cases, or can’t be verified - will produce 200 broken PRs instead of 200 good ones.
Multi-Agent architectures
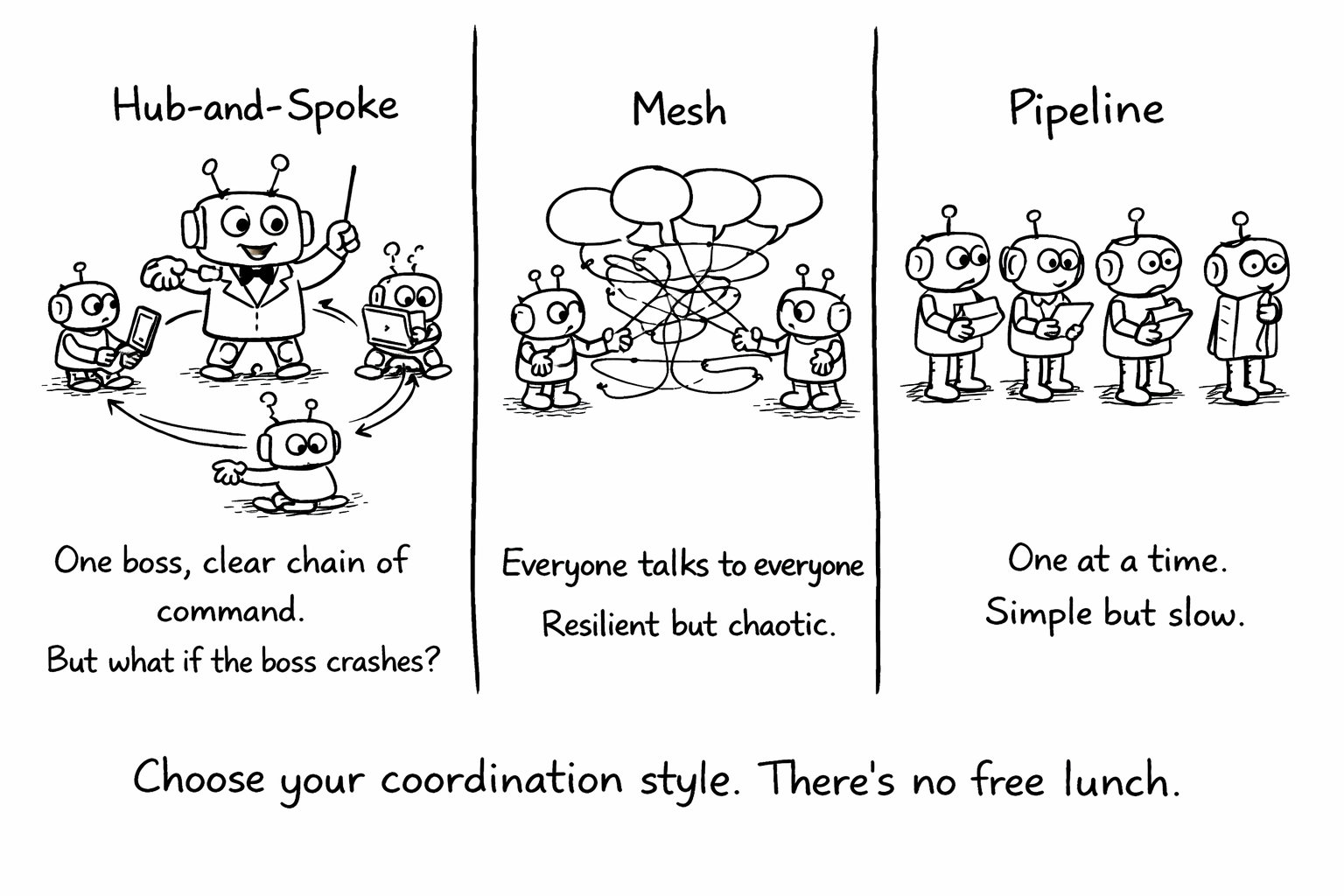
Three architectures dominate production multi-agent systems, each suited to different problems.
Hub-and-spoke uses a central orchestrator that delegates to specialist agents. The orchestrator receives the task, breaks it into subtasks, assigns each to the appropriate specialist, collects the results, and synthesizes a final output. This is the most common pattern because it’s the easiest to reason about and debug. The orchestrator is the single point of control - it decides what happens next, which makes the system predictable. The downside is that the orchestrator becomes a bottleneck and a single point of failure.
Mesh lets agents communicate directly with each other, without a central coordinator. Each agent publishes its capabilities and subscribes to messages from other agents. This is more resilient - no single point of failure - but harder to debug because there’s no central log of decisions. Mesh architectures work well when agents are truly independent and don’t need tight coordination.
Pipeline chains agents sequentially: the output of one becomes the input of the next. A code generation agent produces code, a review agent evaluates it, a test agent writes tests, a documentation agent updates docs. Pipelines are simple and predictable, but they’re slow - each stage must complete before the next begins - and a failure at any stage blocks the entire pipeline.
Task decomposition and handoffs
The hardest part of multi-agent systems isn’t the architecture - it’s deciding how to break a complex task into agent-sized pieces. The decomposition should follow natural boundaries: one agent per concern, one agent per file or module, one agent per skill domain. Tasks that require understanding the relationship between multiple concerns - “refactor the authentication system to support OAuth” - are better handled by a single capable agent than by multiple specialists trying to coordinate.
The handoff protocol - what information passes between agents - is equally important. A handoff that passes only the task description forces the receiving agent to rediscover context. A handoff that passes the full conversation history wastes tokens on irrelevant information. The sweet spot is a structured handoff that includes the task description, the relevant context (files, decisions, constraints), and a summary of what the previous agent did and why. Think of it as a shift handoff in a hospital - the outgoing doctor doesn’t recite the patient’s entire medical history, but they do communicate the current situation, recent actions, and pending concerns.
Failure modes in multi-agent systems
Multi-agent systems have failure modes that don’t exist in single-agent systems. Cascading failures occur when one agent’s bad output becomes another agent’s input - the error propagates and amplifies through the pipeline. Coordination deadlocks occur when two agents are waiting for each other’s output. Resource contention occurs when multiple agents compete for the same tools or API rate limits. Inconsistent state occurs when agents modify the same files without coordination, creating merge conflicts or logical inconsistencies.
Each failure mode requires a specific mitigation. Cascading failures need validation gates between agents - the output of each agent is checked before it becomes the input of the next. Coordination deadlocks need timeouts and fallback paths. Resource contention needs queuing and rate limiting at the tool level. Inconsistent state needs either sequential execution (agents take turns) or optimistic concurrency control (agents work in parallel and resolve conflicts at merge time).
The general principle is that multi-agent systems should be designed for failure. Assume that any agent can fail at any time, and design the system so that failures are detected quickly, contained to the failing agent, and recoverable without losing the work of other agents.
When not to use multi-agent systems
Multi-agent systems are not always the right choice. They add complexity
- more agents means more coordination, more failure modes, and more debugging surface area. Before building a multi-agent system, ask whether a single agent with better context could do the job.
Don’t use multi-agent systems when: The task is linear and doesn’t require different expertise at different stages. A single agent with good context can handle most coding tasks - reading files, writing code, running tests, creating PRs - without needing to delegate to specialists. Adding a separate “test agent” and “review agent” adds coordination overhead without adding capability.
Don’t use multi-agent systems when: The coordination cost exceeds the parallelism benefit. If agents spend more time passing context to each other than they spend doing work, the multi-agent system is slower than a single agent. This is common when tasks are tightly coupled - the output of one agent is the input of another, and the handoff overhead dominates.
Do use multi-agent systems when: Different stages require genuinely different expertise or permissions. A coding agent that generates code and a security agent that reviews it for vulnerabilities have different skill sets and different permission requirements. Combining them into a single agent would require giving the coding agent security expertise (which it may not have) or giving the security agent coding permissions (which violates least privilege).
Do use multi-agent systems when: Tasks can be parallelized. If you need to generate code for five independent modules, five agents working in parallel complete the work 5x faster than one agent working sequentially. The key word is “independent” - if the modules have dependencies, parallelism introduces coordination challenges.
The observability challenge in multi-agent systems
Debugging a single agent is hard. Debugging a multi-agent system is much harder. When something goes wrong, you need to trace the failure across multiple agents, understand how context was passed between them, and identify which agent made the decision that led to the failure.
The solution is distributed tracing with trace ID propagation. Every agent session gets a unique trace ID. When one agent delegates to another, the trace ID propagates to the child session. This creates a tree of traces that shows the complete execution flow - which agent did what, in what order, with what context, and at what cost.
Without trace ID propagation, debugging multi-agent failures is like debugging a microservices system without distributed tracing - you can see individual service logs, but you can’t reconstruct the end-to-end flow. Invest in trace propagation before deploying multi-agent systems to production.
Related Concepts: A2A Protocol (12.1), Agent Loop (17.1) Related Workflows: Setting Up Multi-Agent Workflows (Chapter 23)